
Entwurf eines P2P Social Networks
Warum P2P?
Die großen sozialen Netze von Twitter über Facebook bis Google+ kranken an ihrer zentralen Struktur. Dave Winer hatte sie einmal mit Datensilos verglichen, in denen der Nutzer zwar seine Daten hineinsteckt, aber sie nicht mehr hinausbekommt. Das heißt, der Nutzer ist nicht mehr Herr seiner Daten, wenn Facebook zum Beispiel beschließt, dichtzumachen, oder Google meint, ihn wegen eines Pseudonyms von Google+ auszuschließen, ist alles weg.
Das ist zum Beispiel auch der Grund, warum mein Hauptpublikationstool immer noch mein (selbstgehostetes) Blog ist. Hier gehören mir meine Daten, ich entscheide, was mit ihnen geschieht und wenn mein Provider dicht macht, habe ich (hoffentlich) noch ein Backup und kann woanders alles relativ problemlos neu aufsetzen.
Auf der anderen Seite fehlen (m)einem Blog natürlich viele der netten Dinge, die den Sozialen Netzwerken zueigen sind: Ich kann keine Freundeskreise anlegen, deren Nachrichten verfolgen und kommentieren oder einfach mal einen Knopf drücken, der »Gefällt mir« sagt.
Das war also der Ausgangspunkt meiner Überlegungen: Wie muß ein soziales Netzwerk aussehen, in dem der Nutzer immer und zu jedem Zeitpunkt Herr seiner Daten bleibt, das Kommentare und Like-Buttons ermöglicht und das notfalls sogar auf minimalem Webspace mit statischen Seiten funktioniert?
Webserver auf dem Desktop
Wir waren an solch einer Lösung schon einmal sehr nahe dran. Mit Dave Winers Software Radio Userland feierte schon im Jahre 2000 die Idee eines Webservers auf dem Desktop als Kommadozentrale für alle Webaktivitäten ihren Einstand. Der User bloggte dort und die Software schrieb via FTP (oder XML-RPC) statische Seiten auf einen Webspace der Wahl.
Nun füllt man sein Weblog nicht unbedingt nur von einem Rechner aus. Ich habe zum Beispiel über Jahre den Schockwellenreiter mithilfe von Frontier und einer selbstgeschriebenen, vereinfachten Version von Radio Userland von drei verschiedenen Rechner aus gefüttert. Anfangs hatte ich dazu die Datenbasis (die root-Datenbank) immer auf einem USB-Stick mit mir herumgetragen, nachdem ich aber mehrmals durcheinandergekommen war, weil ich bei der letzten Sitzung vergessen hatte, die aktuelle Version der Datenbank wieder zurück auf den Stick zu überspielen, war mir klar, daß dies keine dauerhafte Lösung sein konnte. Da kam mir die Dropbox gerade recht.
Datenbasis in der Cloud
Denn die Datenbasis in die Cloud – in meinem Falle in die Tropfenschachtel – zu verlegen, bedeutet ja nicht, seine Daten wegzugeben. Sie liegen ja weiterhin, nun aber »ordentlich« synchronisiert, auf meinen Rechnern und sind auch offline nutzbar. Der Sicherheitsaspekt spielt keine besondere Rolle, da es ja sowieso nur Daten sind, die ich für eine Veröffentlichung vorgesehen habe.
Ein Nachteil bei der Dropbox und ähnlichen Lösungen ist sicher, daß Konflikte auftreten können, wenn mehr als ein Nutzer gleichzeitig auf die Daten zugreift. Ich gehe allerdings davon aus, daß die Mehrheit der Nutzer des von mir angedachten sozialen P2P-Netzwerks Einzelnutzer sind. Wenn dies nicht der Fall ist, muß man an Stelle der Dropbox vielleicht ein öffentliches Repositorium wie zum Beispiel GitHub verwenden. Das macht die Sache zwar ein wenig komplizierter, löst aber das Problem der Zugriffskonflikte.
RSS als Nachrichtenstrom
Radio Userland hatte aber noch etwas, was es in die Nähe heutiger sozialer Netze rückt: Es hatte einen integrierten RSS-Feed-Reader, der nicht – wie zum Beispiel Googles Reader – die einkommenden Feeds nach den Quellen gruppierte, sonder sie als fortlaufenden zeitlichen Nachrichtenstrom anzeigte, ähnlich wie heute auch Google+, Facebook oder Twitter.
Das wäre die erste Komponente eines P2P-Netzes. Ich abboniere die RSS-Feeds meiner »Freunde« und wie auf Twitter, Facebook oder Google+ rauschen deren Nachrichten als River of News (Winer) an mir vorbei.
Publishing-Interface
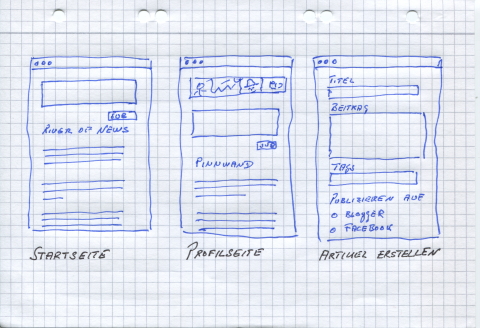
Die zweite Komponente ist natürlich ein Publishing Interface. Das sieht erst einmal kaum anders aus, als die gewohnten Weblog-Eingabmasken. Und das Einzige, was es erst einmal herausschreiben muß, ist nichts anderes als einen RSS oder Atom-Feed, den die Software automatisch auf einen Webspace meiner Wahl der Öffentlichkeit zugänglich macht.
Natürlich ist mehr möglich: Zum einen könnte die Software – wie damals schon Radio Userland – alle oder auch nur einen Teil der Beiträge als Weblog mit statischen Seiten herausschreiben. Aber auch ein automatisches Füttern von Weblog-Software via API oder XML-RPC wäre möglich. Und es wäre dann völlig egal, ob es ein selbstgehostetes WordPress-Blog ist oder ich ein Blog bei einem Bloghoster wie Blogger oder Typepad vollschreibe. Die Originaldaten liegen ja weiterhin auf meinem Desktop, das Blog ist nur ein zusätzlicher Distributionskanal.
Und last but not least kann ich auch die vielgeschmähten sozialen Netzwerke via ihrer APIs damit bedenken. Und ich muß diese ja nicht mit all meinen Ergüssen vollmüllen. So bin ich zum Beispiel Teil einer netten Agility-Community auf Facebook und die Software sollte es so einrichten können, daß alle Beiträge, die mit Agility getagged sind, automatisch als Crossposting auf Facebook landen.
Das setzt natürlich einiges an Konfiguration voraus, die man nicht bei jedem Post vornehmen möchte. Daher sollte es eine Default-Konfiguration geben, in der der Nutzer festlegt, welche Sozialen Netze er bedienen möchte (im Minimalfall schreibt die Software eben nur einen RSS-Feed heraus), welche wie getaggten Beiträge in welchen Netzen landen und so weiter. Aber natürlich sollte der Nutzer die Möglichkeit haben, diese Konfiguration bei jedem Post überschreiben zu können.
Und so schweben mir auch zwei parallele Nutzerschnittstellen für die Postings vor: Eine einfache, die ähnlich den bisherigen sozialen Netzen ein simples und schnelles Posten erlaubt und die – weil der Nutzer das so gewohnt ist – über dem Nachrichtenstrom schwebt.
Und ein mehr elaboriertes Interface, das ähnlich der »Artikel erstellen«-Seite von WordPress, dem Nutzer mehr Möglichkeiten gibt, in die Konfiguration einzugreifen und diese für diesen einen Artikel anzupassen, Tags oder Kategorien zu vergeben und die Publikationspfade zu beeinflussen.
Schließlich sollte es natürlich noch eine Seite geben, die nur meine eigenen Aktivitäten anzeigt, ähnlich der Pinnwand von Facebook. Denn gerade, wenn ich mich entschließe, kein Blog zu führen, sondern »nur« einen RSS- oder Atom-Feed herauszuschreiben und vielleicht auch noch Facebook zu füttern, wäre diese Seite eine Art Blogersatz oder mehr ein Tagebuch meiner Aktivitäten nur für mich.
Und auch über dieser Seite sollte es – wie bei Facebook – die vereinfachte Eingabemaske geben. Denn das ist eines der Dinge, die mich bei Google+ regelmäßig ärgern: Ich kann Eingaben nur von der Startseite aus tätigen, nicht aber von meiner Profilseite.
Kommentare und »Gefällt mir«-Knöpfe
Bleibt nur noch das Problem der Kommentare und des »Like-Buttons«. Doch wenn man die Idee des RSS- oder Atom-Feeds konsequent zu Ende denkt, bietet sich auch dieser hier als Lösung an. Obwohln es sicher möglich ist, bestehende, wenn auch selten genutzte Tags der Feeds umzudefinieren, um das Erwünschte zu erreichen, schlage ich – einfach weil es sauberer ist – eine Namespace-Erweiterung (ähnlich der iTunes-Erweiterungen) vor: Für die Kommentare werden (mindestens) zwei zusätzliche Tags benötigt. Einmal einen <comment_title>-Tag und einen <comment_url>-Tag. Und dann bekommt jeder einzelne Feedbeitrag auf der Startseite einen Kommentar-Knopf, der ein Textfeld öffnet, in dem der Kommentar eingetippt werden kann.
Und erst einmal geht dieser Kommentar dann – wie jeder gewöhnliche Beitrag auch – als RSS-Feed auf die Reise. Nur, daß er die beiden vorgeschlagenen zusätzlichen Tags enthält. Was der jeweilige Reader nach Erhalt damit anstellt, bleibt ihm überlassen: Entwender er reiht sie – ähnlich Twitter – wie jeden anderen Beitrag auch in den Zeitstrom ein oder er behandelt sie wie Facebook oder Google+, das heißt, die Kommentare werden als Threads den jeweiligen Beiträgen zugeordnet.
Im zweiten Fall können die Kommentare dann natürlich auch beim nächsten Herausschreiben des Blogs auf diesem angezeigt werden – und das, ohne daß auf dem Server des Hosters irgendein Skript oder ähnliches laufen müßte.
Analog kann mit dem »Gefällt mir«-Knopf verfahren werden. Auch beim Einsatz dieses Elements müssen (mindestens) zwei zusätzliche Tags für den Feed bereitgestellt werden: Einmal einen <like_url>- und dann natürlich auch einen <like_title>-Tag. Und ob der lesende Server dann stolz die Anzahl der »Likes« zählt und anzeigt oder ob er es einfach ignoriert, bleibt wieder ihm überlassen.
Und ebenso geht das »Teilen« vonstatten: Ein »Share«-Button zu jedem Feedeintrag, ein zusätzlicher <share_url>- und ein <share_title>-Tag im Feed des Nutzers und dann wird der Beitrag erneut im Feed des Nutzers publiziert.

Natürlich erfordert dies ein gewisses Umdenken. Kommentieren, Teilen oder die Zustimmung per Knopfdruck findet nicht mehr auf dem Server des Autors statt, sondern im Feedreader des Lesers. Aber das dies funktionieren kann, hat uns Googles Feedreader ja vorgemacht.
Auf den Schultern eines Riesen
Natürlich ist dies nicht alles auf meinem Mist gewachsen. Dave Winer, der seine Frontier-Fork, den 0OPML-Editor, bis an die Schmerzgrenze ausreizt, hat vieles von dem vorgedacht: Es fing ja schon mit Radio Userland an, dann teilte ich seine Bedenken gegenüber den Datensilos der Sozialen Netzwerke. Von ihm stammt der River of News, die Idee, RSS als Publishing-Format zu nutzen (was bei ihm, der sich ja gerne als »the father of RSS« bezeichnen läßt, auch nicht wundert) und mit Radio2 hat er diese Idee – auf Basis des OPML-Editors – auch weitgehend umgesetzt.
Allerdings geht Winer von einer Community aus, die sich weitesgehend um seine Software dreht, den Gedanken eines konsequenten Peer-to-Peer-Netzes hat er nicht zuende gedacht. Dennoch verdanke ich ihm viel und möchte das daher nicht unerwähnt lassen.
Ich bin sicher, daß man mit Winers OPML-Editor sehr schnell einen Prototypen dieser Ideen zusammenbasteln könnte – Winer hat zwar das auf meine Anregung aufgenommene Static Site Framework wieder aus der Standard-Distribution des OPML-Editors entfernt (warum eigentlich?), aber das läßt sich sicher leicht nachrüsten. Aber natürlich geht das mit nahezu jedem anderen Stück Web-Framework auch: Ob Django, Ruby on Rails, irgendeine PHP-Anwendung unter MAMP oder XAMPP oder ein aufgebohrtes DokuWiki … alles, was irgendwie eine Serverumgebung auf dem Desktop realisiert und RSS-Feed herausschreiben kann, eignet sich als Grundlage.
Und unter Umständen kann man – wie ich weiter unten ausgeführt habe – sogar auf die Server-Umgebung verzichten. Das einzige, was benötigt wird, ist ein Stück Software, das mit RSS- und ATOM-Feeds (inklusive der von mir vorgeschlagenen minimalen Ergänzungen) umgehen kann. Was das für eine Software ist und auf welchem Rechner unter welchem Betriebssystem sie läuft, ist zum Funktionieren dieses P2P Social Networks völlig egal.
Zusammenfassung
Die von mir vorgeschlagene Lösung hat den Vorteil, daß sie einmal eine konsequente Trennung von Redaktionsserver (das ist in diesem Fall der Server auf dem Desktop) und Produktionsserver – im Falle der minimalistischsten Lösung ist dies der Server, auf dem der RSS- oder Atom-Feed liegt – vornimmt. Dabei braucht der Redaktionsserver nicht einmal unbedingt ein wirklicher Server zu sein. Ich bin mir sicher, daß Elisp-Bastler es auch schaffen, zum Beispiel den Org-mode des Emacs so aufzubohren, daß er als »Redaktionsserver« einsetzbar ist. Lediglich das Einfahren des RSS-Feeds müßte dann vermutlich manuell vom Nutzer angestoßen werden.
Zum zweiten – und das ist mir das Wichtigste – behält der Nutzer die volle Kontrolle über seine Beiträge und Dateien. Artikel, Bilder, Videos … all dies liegt und bleibt auf dem Desktop des Nutzers, die jeweiligen Clients erhalten bestenfalls eine Kopie. Natürlich bleibt es dem Nutzer unbenommen, falls zum Beispiel sein Hoster nicht genug oder zu teuren Speicherplatz zur Verfügung stellt, auch Flickr, YouTube, Picasas Web Album oder andere Dienste zu nutzen und seine Multimedia-Dateien darüber einzubinden. Die Software sollte dies ermöglichen, in dem sie zum Beispiel alle Bilder, die in einem dafür vorgesehenen Ordner liegen, zu Flickr hochlädt; aber sie sollte trotzdem eine Kopie der Daten auf dem Desktop behalten.
Und auch das Publizieren in der Cloud bereitet so keine Kopfschmerzen mehr. Warum sollte man nicht anstelle eines »normalen« ISP wie Host Europe oder Strato seine statischen Daten zu Amazon S3 hochladen. Egal, wo es mir nicht mehr gefällt – mit einer Änderung in der Konfigurationsdatei und einem Knopfdruck kann ich mit all meinen Daten umziehen.
Mit diesem Entwurf habe ich einen langen Weg hinter mir. Ging ich bei meinen ersten Überlegungen (2003 in einer Keynote zur Blogtalk in Wien) noch davon aus, daß ein Community-Server und ein Trackback-Ping notwendig seien, um ein P2P Social Network zu schaffen, konnte ich zwar in späteren Überlegungen den Community-Server eliminieren, setzte dafür aber auf XMPP (Jabber) als verbindendes Protokoll. Erst langsam ging mir auf, daß die einfachste Lösung die sicherste Lösung ist und eine Lösung, die nur RSS resp. Atom als verbindendes Protokoll benötigt … einfacher geht es kaum.
Ich glaube nicht, hiermit den Stein der Weisen gefunden zu haben. Aber ich wollte die Idee einfach einmal niederschreiben, und sei es nur, um irgendjemanden zuvorzukommen, der sich so etwas patentieren lassen und damit Geld verdienen will. Denn Trivialpatente sind ja gerade en voque in dieser seltsamen Zeit.