
3D-Scans von Keilschrifttafeln — Ein Werkstattbericht
Autoren: Jörg Kantel (MPIWG Berlin), Peter Damerow (CDLI, MPIWG Berlin), Sarah Köhler (FSU Jena, Institut für Alt-Orientalistik), Christina Tsouparopoulou (CDLI Berlin und Los Angeles)
Dieser Bericht dokumentiert work in progress. Er berichtet von der Arbeit, die am Max-Planck-Institut für Wissenschaftsgeschichte (MPIWG) in Berlin zusammen mit der institutsübergreifenden Cuneiform Digital Library Initiative (CDLI) in Berlin und Los Angeles und der Hilprecht-Sammlung der Friedrich-Schiller-Universität Jena (FSU) am Institut für Sprachen und Kulturen des Vorderen Orients durchgeführt wird, um Keilschrifttafeln dreidimensional einzuscannen und im World Wide Web zugänglich zu machen. Obwohl sich erste Erfolge abzeichnen, sind noch viele Fragen offen und einiges auch noch nicht abschließend geklärt. Das betrifft insbesondere die Frage der Web-Repräsentation der eingescannten Objekte. Trotzdem glauben wir, daß ein Bericht über unsere Herangehensweise an dieses Projekt und über die bisherige Arbeit Sinn macht, einerseits als Anregung für ähnliche 3D-Projekte und andererseits weil wir vermuten, daß die Probleme, die das Projekt aufwirft, durchaus typisch sind für andere Großprojekte in der Wissenschaft, sodaß dieser Bericht als Hilfestellung dienen kann.
Was ist die CDLI?
Keilschrifttafeln gehören neben den ägyptischen Hyroglyphen zu den ältesten schriftlichen Zeugnisse der Menschheit. Sie dienten zahlreichen Kulturvölkern des alten Orients (Sumerer, Akkader, Babylonier, Hethiter, Assyrer und andere) in der Zeit von etwa 3.000 vor unserer Zeitrechnung bis zum Beginn des ersten Jahrhunderts unserer Zeitrechnung als bevorzugte Schriftform. Die Zeichen wurden mit einem Holz- oder Rohrgriffel in weichem Ton eingedrückt und bestehen in ihren Grundelementen aus waagrechten, senkrechten und schrägen Keilen. Das Trägermaterial, feuchter und nach dem Eindrücken der Zeichen getrockneter Ton, ist von Natur aus sehr haltbar, so daß solche Keilschrifttafeln auch lange historische Zeiträume unversehrt überstehen können. Die geschätzte Zahl der bislang ausgegrabenen Keilschrifttafeln beläuft sich auf mehr als 500.000 Objekte, von denen ein großer Teil bis heute noch nicht wissenschaftlich publiziert wurde. Diese Tafeln liegen weltweit verstreut in den öffentlichen und privaten Sammlungen der Museen, der Archive und der Depots der Sammler. Aufgrund ihrer Grabungs- oder Raubgrabungsgeschichte sind vielfach zusammengehörende Tafeln aus ihrem archäologischen Kontext gerissen und auf diverse Sammlungen verstreut worden, so daß eine zusammenhängende Untersuchung sich oftmals als sehr schwierig erweist und mit kostspieligen Reisetätigkeiten verbunden ist.
Die Cuneiform Digital Library Intitiative ist ein joint venture zwischen dem Max-Planck-Institut für Wissenschaftsgeschichte und der University of California at Los Angeles (UCLA) und wird geleitet von Robert K. Englund (Los Angeles) und Peter Damerow (Berlin). Sie hat es sich zur Aufgabe gesetzt, die vorhandenen Keilschrifttexte zu katalogisieren und wenn möglich in Bildform, als Umzeichnung und in Fom einer Transliteration im Netz zur Verfügung zu stellen. Bisher sind etwa 225.000 Texte katalogisiert und etwa 50.000 Tafeln zweidimensional eingescannt und im World Wide Web zugänglich gemacht worden. Außerdem stellt die CDLI eine webbasierte Umgebung für die kollaborative Transkription, Transliteration, Übersetzung und Publikation der Tafeln zur Verfügung.
Warum 3D?
Aufgrund ihres Alters und ihrer Geschichte sind die gefundenen Tafeln häufig beschädigt und schwer zu entziffern. Bei der Transliteration der Tafel versuchen Altorientalisten daher in der Regel, mit Hilfe wechselnder Beleuchtung eine bessere Lesbarkeit der Tafeln zu erreichen, um besser entscheiden zu können, was Zeichen und was Beschädigung ist. Zweidimensionale Scans auch in hoher Auflösung reichen daher oft nicht aus, da sie unter einer einheitlichen Beleuchtung angefertigt werden. Zwar gibt es auch bei Altorientalisten eine Standard-Beleuchtung (schräg von links oben), doch diese muß variiert oder, wie dies beim aufwendigen Photographieren der Tafeln geschieht, durch zusätzliche Lichtquellen ergänzt werden, um alle Teile einer Tafel mit einer oftmals unebenen Operfläche in gleicher Weise lesbar zu machen.
Die meiste Software für dreidimensionale Objekte erlaubt es, ein Licht oder mehrere Lichter im Viewer zu setzen und auch den Kamerastandpunkt zu verändern. So kann die Arbeitsweise des Altorientalisten virtuell nachgebildet werden, ohne daß der Forscher das Objekt in die Hand nehmen oder gar zu seinem Standort reisen muß. Eine angepaßte virtuelle Arbeitsumgebung kann somit perfekt die Arbeitsweise des Wissenschaftlers nachbilden und ermöglicht so eine größere Produktivität und bietet, wenn erst einmal genügend dreidimensional eingescannte Tafeln zur Verfügung stehen, auch eine Plattform zum Vergleich verschiedener Tafeln und ihrer Eigenschaften.
Auswahl des Scanners
Nach einer umfangreichen Evaluation kamen drei Hersteller von 3D-Scannern und der dazugehörenden Software in die engere Auswahl und wurden jeweils getrennt für eine eintägige Präsentation in das MPIWG eingeladen, wo sie ihre Geräte aufbauen und ein oder mehrere Keilschrifttafeln oder deren Abgüsse einscannen sollten.
Um ein realistisches Bild von der Qualität der Produkte zu erhalten, wurde eine komplizierte Tafel ausgewählt, die nicht nur stark beschädigt, sondern auch noch aus Bruchstücken zusammengesetzt und teilweise gefälscht war. Das Scan-Ergebnis sollte es natürlich er-möglichen, diese Strukturen und auch die Fälschung zu erkennen, genauso, wie es am realen Objekt möglich ist.
Das Produkt der ersten Firma (Produkt A) hatte eine zu geringe Auflösung, die die Software durch einen Glättungsvorgang zu kompensieren suchte. Dies mag in anderen Bereichen sinnvoll sein, ist jedoch für die Anwendung auf Keilschrifttafeln nicht geeignet, da darunter die Lesbarkeit der Zeichen massiv leidet.
Das Produkt der zweiten Firma (Produkt B) hatte auch nur eine Auflösung von 1280 x 960 Pixel (also etwa 1,2 Megapixel), doch die Glättung, die die Software auch versuchte, konnte abgestellt werden. Dafür aber kam die Software mit der Farbdarstellung nicht zurecht, da sie versuchte, nachträglich Photos der Tafel als {\em Texture} auf das dreidimensionale Objekt der Tafel zu mappen. Diese Vorgehensweise ist im 3D-Bereich zwar durchaus üblich (eigentlich sogar eher der Normalfall), bei der zerklüfteten und unregelmäßigen Struktur der Keilschrifttafeln führte dies jedoch zu keinem befriedigenden Ergebnis. Und Farbe ist essentiell für die Arbeit mit den Tafeln. Denn sie gibt eine zusätzliche Information, die dem Wissenschaftler bei der Erforschung der Tafel hilft und daher in hinreichender Qualität zur Verfügung stehen muß.
Lediglich das Produkt C, der smartSCAN3D-HE der Firma Breuckmann aus Meersburg konnte uns überzeugen. Er scannt in sehr hoher Auflösung (5 Megapixel) und hält sich bei der Glättung zurück. Alleinstellungsmerkmal ist aber, daß der Scanner die Farbinformation zu jedem eingescannten Punkt speichert und nicht versucht, nachträglich eine Texture zu mappen. Dies erhöht zwar Dateigröße wie auch den Zeitaufwand beim Scannen, das Ergebnis erfüllte aber weitestgehend unsere Erwartungen und so wurde die Anschaffung dieses Scanners beschlossen und vom zuständigen Direktor Jürgen Renn genehmigt.
Die Hardware

Der smartSCAN3D-HE ist ein Streifenlichtscanner, kein Laserscanner, der — wie oben schon erwähnt — die Farbinformationen mit den Punkten der Scans abspeichert. Er besteht aus zwei Kameras mit wechselbaren Objektiven, einem Projektor mit wechselbaren Objektiven und zwei Positionierlasern zur Einstellung des richtigen Arbeitsabstandes. Er muß auf einem stabilen Stativ montiert werden und wird über eine Kontrolleinheit mit dem Scan-Rechner verbunden. Ebenfalls mit dieser Kontrolleinheit verbunden ist ein massiver Drehteller. Scan-Rechner ist eine 2-Core-Maschine von Dell mit Windows XP. Um die Breuckmann-Software OPTOCAT starten zu können, wird aus Kopierschutzgründen ein Dongle benötigt.
Mitgeliefert wurden drei Objektivsätze mit verschiedenen Brennweiten, von denen wir aus Gründen der höchstmöglichen Auflösung aber nur den Objektivsatz für das kleinste Meßfeld (125 mm) verwenden.
Außerdem gehörten zum Lieferumfang zwei Kalibriertafeln, von denen eine zweiseitig nutzbar ist, so daß damit alle drei Meßfelder kalibriert werden können.
Der Rechner selber war eigentlich von Anfang an zu schwachbrüstig ausgelegt, so daß wir — nachdem unsere Überlegungen zum Workflow (siehe weiter unten) sowieso die Anschaffung zusätzlicher Rechner und Softwarelizenzen erforderten — eine Aufrüstung vornahmen.
Diese neuen Rechner sind erst seit ein paar Tagen im Einsatz, daher können wir eine Einschätzung, wie weit die zusätzliche Rechenleistung den Scanvorgang beschleunigt, noch nicht abgeben.
Die Software
Die OPTOCAT-Software der Firma Breuckmann, die für das Scannen und Bearbeiten der Rohdaten zuständig ist, ist eigentlich sehr gut durchdacht und auch in der Benutzerführung konsequent. Allerdings ist ihr Fokus weniger auf den wissenschaftlichen Betrieb ausgerichtet, als auf Arbeiten, wie sie in der Industrie anfallen. Das gilt noch im verstärkten Maße für das umfangreiche, mitgelieferte Handbuch. Die Lernkurve für einen sachgemäßen Umgang mit der Software ist daher zu Beginn ziemlich steil und einige Male standen wir frustiert vor unseren Ergebnissen, die eher an Kleinsche Flaschen als an Keilschrifttafeln erinnerten.
Der Workflow
Schon nach den ersten Testreihen war uns klar, daß wir den Workflow in den eigentlichen Scan- und in einen Post-Processing-Vorgang aufteilen müssen, um überhaupt einen akzeptablen Durchsatz zu erreichen. Und nachdem wir herausgefunden hatten, daß der Scan-Vorgang in einem beschleunigten Preview-Mode, in dem nur jedes 3. Pixel angezeigt wird, durchgeführt werden kann, ohne daß die Qualität darunter leidet — die Originaldateien in der hohen Auflösung bleiben trotzdem erhalten —, fanden wir auch schnell heraus, wo die Schnittstelle zwischen den beiden Vorgängen liegen kann.
Dabei kam uns zu Hilfe, daß der Scanner beim Scan-Vorgang erst einmal Bilddateien abspeichert (mit der Endung .abs), die als Grundlage für alle weiteren Arbeiten dienen. Daraus berechnet er die von Breuckmann so genannten Container-Dateien (.ctr), die dann tatsächlich nur die Informationen für jedes dritte Pixel haben. Diese reichen aber aus, um die für das Scannen notwendigen groben Säuberungen und Alignments durchzuführen. Dies ist der erste Teil des Workflows, den wir im weiteren den Scan-Vorgang nennen.
Für die weitere Arbeit ist der Scanner nicht mehr erforderlich, sondern nur noch ein möglichst leistungsfähiger Rechner mit der OPTOCAT-Software. Diesen Vorgang haben wir Post-Processing genannt und er kann auch an anderer Stelle als an dem eigentlichen Scan-Ort durchgeführt werden.
Daher ist unsere zur Zeit noch nicht realisierte Idee, daß ein Team vor Ort scannt und ein weiteres Team am Institut das Post-Processing durchführt. Bei einfachen Tafeln kann so der Scan-Vorgang auf ca. 20 Minuten gekürzt werden. Das Post-Processing dauert ca. zwei bis drei Mal so lange. Daher besteht unsere gesamte Scan-Ausrüstung nach einer Nachbestellung nun aus einem Scan- und drei Post-Processing-Rechnern, die alle mit der OPTOCAT-Software ausgestattet sind.
Der Scan-Vorgang

Nach langen Testreihen haben wir folgenden Scan-Vorgang als optimal eingestuft: Zuerst einmal wird die Tafel mit der Vorderseite flach auf den Drehteller gelegt und nach jedem Scan wird der Teller um 60 Grad weitergedreht, so daß 6 Scans in einem Durchgang erledigt werden. Das Alignment erfolgt hierbei automatisch, da die Software über die Control-Unit mit dem Drehteller verbunden ist.
Anschließend wird die Tafel gedreht und die Rückseite auf die gleiche Weise gescannt. Hier muß man der Software mitteilen, daß sich die Lage des Scan-Objekts verändert hat und wird nach dem ersten Scan zu einem manuellen Alignment aufgefordert. Das weitere Alignment erfolgt dann wieder automatisch.
In dieser Lage werden zwar die kritischen Ränder der Tafel sehr gut erfaßt, die jeweilige Vorder- und Rückseite liegt aber vielfach außerhalb des eigentlichen Schärfebereichs des Scannermeßfeldes. Daher wird von diesen beiden Seiten jeweils ein Scan manuell durchgeführt. Hierbei kommt eine selbst entwickelte Konstruktion mit Hilfe von Fischertechnik-Elementen zum Einsatz, die die Seiten annähernd parallel zu den Objektiven ausrichtet.
Bei gut erhaltenen Tafeln reichen diese 14 Aufnahmen aus, Tafeln mit tiefen Keilen und/oder Rissen müssen unter Umständen an den kritischen Stellen noch einmal manuell nachgescannt werden. Hierfür gibt es keine konkreten Regeln, hier hilft nur die Erfahrung der mit dem Scannen befaßten Mitarbeiterin oder des mit dem Scannen befaßten Mitarbeiters.
Größere Tafeln müssen in mehreren Streifen eingescannt werden. Hier wird die Zahl der benötigten Aufnahmen sehr schnell sehr groß und auch die Anforderungen an die Rechenleistung wachsen rapide. Als ressourcensparende Lösung hat es sich bewährt, immer nur die Scans zu laden, die für ein Alignment benötigt werden. Daher lohnt es, sich vorher über die Scanreihenfolge Gedanken zu machen und über den gesamten Scanvorgang ein Protokoll zu führen.
Post-Processing
Beim Post-Processing werden erst einmal aus den Photo-Dateien (.abs) neue Container-Files (.ctr) generiert, diesmal in hoher Auflösung. Leider sind alle vorhergehenden Säuberungen damit wieder verschwunden, so daß beim eigentlichen Scannen wirklich nur die Stellen gesäubert werden sollten, die zum Alignment erforderlich sind.
Nun kommt es darauf an, alle nicht zum Objekt gehörenden Teile, aber auch unscharfe oder verrauschte Bereiche aus dem Objekt zu entfernen. Und auch für die Frage, was entfernt werden kann oder muß und was nicht, gibt es bestenfalls Faustregeln. Hier spielt die Erfahrung der Bearbeiterin oder des Bearbeiters eine große Rolle. An dieser Stelle wird man allerdings von der Software wirklich gut unterstützt, die Bedienung ist einfach und intuitiv.
Danach kann man noch einmal ein abschließendes Alignment durchführen und anschließend die Meshes endgültig berechnen lassen. Dieser Teil ist eher rechen- denn arbeitsintensiv (die Berechnung dauert oft mehrere Minuten bis zu einer Virtelstunde), so daß wir uns vorstellen können, daß eine Mitarbeiterin oder ein Mitarbeiter parallel an zwei Vorgängen arbeiten kann.
Für das Endergebnis unterstützt die Software der Firma Breuckmann neben vielen anderen sowohl das offene PLY-Format (eine um die Farbkompenente erweiterte Version des ebenfalls offenen STL-Formats) als auch das vom W3C zum Standard erhobene VRML resp. X3D.
Da es sinnlos ist, einmal dreidimensional gescannte Tafeln noch einmal zweidimensional einzuscannen, entwickelte die Firma Breuckmann für uns ein Makro, das automatisch Screenshots von den Objekten erstellt, die der gewohnten side view nach den Standards der CDLI entsprechen. Diese sechs kreuzweise angeordneten Bilder der Scans werden im CDLI-Jargon auch archival fat-cross representation of tablets oder einfach fat cross genannt.
Erste Ergebnisse

Schon nach kurzer Einarbeitungszeit waren die erzielten Ergebnisse recht ansehnlich. Manchmal hatten wir sogar den Eindruck, daß die Screenshots der dreidimensionalen Modelle, die mit dem oben erwähnten Makro geschaffen wurden, die üblichen, zweidimensionalen Scans an Schärfe und Deutlichkeit übertrafen. Das hat sicher auch damit zu tun, daß das Makro es uns erlaubt, für jeden Screenshot noch einmal individuell die Lichter zu setzen.
Dies haben wir an dieser Tafel (HS 134, Abbildung oben) aus der Hilprecht-Sammlung ausprobiert. Die Tafel enthält auf der linken Seite Rollsiegel. Rollsiegel sind bei weitem nicht so tief in den Ton eingedrückt, wie normale Keilschrift-Zeichen und daher oft schwer zu erkennen und zu interpretieren. Wie noch diese gegenüber dem Original-Screenshot stark verkleinerte Abbildung oben zeigt, ist selbst bei ihr das Siegel noch zu erkennen. Im Originalscan mit einem guten Viewer (zum Beispiel den der Firma Breuckmann oder mit Meshlab, siehe nächsten Abschnitt) betrachtet und mit einem zusätzlichen Streiflicht versehen, tritt das Rollsiegel deutlich hervor.

Mindestens genauso überzeugend ist die Ansicht der linken Seite dieser Tafel (Abbildung oben), die ebenfalls mit einem Rollsiegel versehen ist. Hier ist selbst in der kleinen Abbildung deutlich der Landarbeiter mit seinem Pflug und den beiden Zugtieren zu erkennen. So etwas sieht sonst der Wissenschaftler oft erst, wenn er das Original in den Händen hält.
3D-Daten - und nun?
Als Ausgabeformat für die fertigen 3D-Objekte haben wir uns vorläufig für das offene PLY-Format (PoLYgon File Format), eine Weiterentwicklung des ebenfalls offenen STL-Formats (Stanford TriangLe Format) entschieden. Eine weitere Option ist der W3C-Standard VRML (Virtual Reality Modelling Language) resp. deren Nachfolger X3D (eXtended 3D Format). Die Konvertierung von PLY nach VRML wird von der Breuckmann-Software schnell und problemlos erledigt.
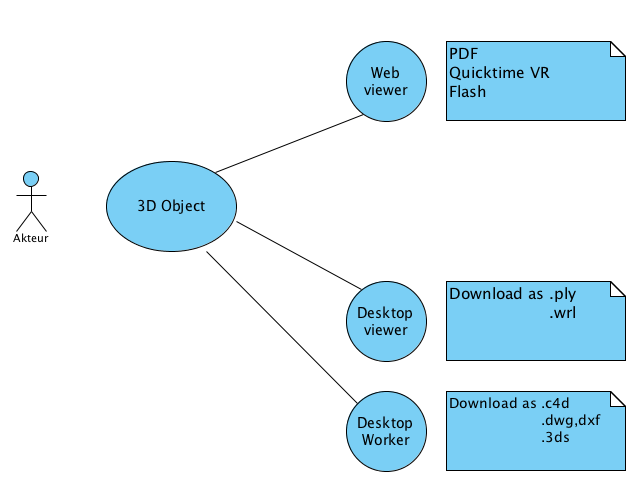
Bei der Nutzung der 3D-Daten gehen wir von folgendem Szenario aus (Abbildung oben):
Der Nutzer betrachtet einen {\em Thumbnail} der Keilschrifttafel im Browser. Das kann tatsächlich »nur« eine verkleinerte Abbildung der Tafel sein, aber es sind auch kleine, komprimierte 3D-Darstellungen in PDF, QuickTime VR oder Flash denkbar.
Für eine genauere Inspektion lädt sich der User die PLY- und/oder VRML-Datei herunter. Wir haben uns aus Gründen, die weiter unten erläutert werden, entschieden, {\bf beide} Formate zum Download anzubieten. Als {\em Desktop Viewer} kommen dann der Breuckmann-Viewer und/oder MeshLab in Frage, die beide sowohl PLY- als VRML-Dateien lesen können. Diese zwei Programme werden weiter unten ausführlich vorgestellt.
Schließlich gibt es noch den {\em use case}, daß ein Anwender die Daten weiterverarbeiten will, sei es, um sie für Präsentationen aufzubereiten, sei es, um sie mit anderen 3D-Elementen zu kombinieren oder sie mit zusätzlichen Lichtern zu versehen. Hier muß der Nutzer die Daten erst einmal in das Anwendungsformat seiner Wahl konvertieren, zum Beispiel .c4d oder .dxf (auch dazu weiter unten mehr).
Aufbereitung der Daten für das Web
Die Aufbereitung der Daten für das Web haben wir bisher mit dem Programm Cinema 4D durchgeführt. Neben der Tatsache, daß das Know How für die Bedienung dieses Programms wenigsten ansatzweise im Umkreis des Projekts vorhanden war, überzeugte Cinema 4D vor allem durch die vielfältigen Import- und Exportmöglichkeiten, die zumindest auf dem Papier existierten.
Allerdings konnte Cinema 4D zuerst einmal die riesigen PLY-Meshes nicht laden. Dagegen konnte die Software die VRML-Daten beinahe problemlos einlesen. Allerdings gingen die Farbinformationen beim Import verloren. Ob dies ein Bedienungsfehler von uns war oder ob Cinema 4D mit den Farbinformationen an jedem Punkt (anstelle von Texturen) nicht zurechtkommt, konnten wir bisher noch nicht abschließend klären.
QuickTime VR
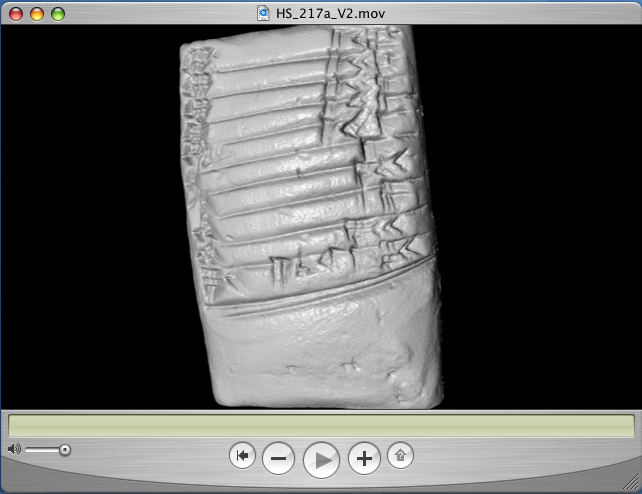
Von hier aus konvertierten wir die Tafel nach QuickTime VR (QuickTime Virtual Reality). Das ist ein proprietäres Format der Firma Apple, mit dem vorgerenderte Bilder in einer Quasi-3D-Darstellung angezeigt werden können.
Obwohl proprietär, hatten wir QuickTime in die engere Wahl genommen, da das Format und vor allem das Browser-Plugin, mit dem QuickTime-Filme im Web betrachtet werden können, weit verbreitet ist.
Aus einer 160 MB großen VRML-Datei konnten wir ein etwa 20 MB großes QuickTime-Movie erzeugen, daß sich auch ziemlich problemlos — eine schnelle Datenleitung vorausgesetzt — im Browser einbinden und betrachten ließ.
Da QuickTime VR tatsächlich nur vorgerenderte Bilder liefert, ist diese Darstellung nur für eine Voransicht und zu Präsentationszwecken geeignet (wenn es uns gelingt, daß Problem der fehlenden Farbdarstellung zu lösen). Für diese Anwendungsfälle ist es dann unter Umständen sicher sinnvoll, eine verkleinerte Darstellung zu wählen, um die Dateigröße weiter zu reduzieren.
PDF 3D
Seit der Version 7 ist es möglich, dreidimensionale Objekte in das bekannte PDF (Portable Document Format) der Firma Adobe einzubinden und zu betrachten. Hierzu benötigt man zur Konvertierung die Software Adobe Acrobat Professional Extended, in unserem Fall in der Version 9. Auch diese Software war nicht in der Lage, die PLY-Dateien einzuladen, der Computer stürzte jedesmal mit einem out of memory-Fehler ab. Aber auch die VRML-Dateien brachten ähnliche Probleme. Erst auf einem 64-Bit-Rechner mit 20 GB Hauptspeicher gelang uns die Konvertierung. Leider ging auch hier die Farbinformation beim Konvertieren verloren (aus vermutlich ähnlichen Gründen wie bei Cinema 4D).
Dafür war dann der Komprimierungsfaktor sehr eindrucksvoll. 160 MB VRML wurden zu 4 MB PDF heruntergerechnet. Das liegt sicherlich an der Technik, die Adobe Live Rendering nennt und die dann auch gleich die Nachteile dieses Formats zeigte. Zwar ist der Download der PDF-Datei sehr schnell, doch beim ersten Aufruf rechnet die Software bis zu mehreren Minuten, bevor sie die erste Darstellung der Tafel zeigt. Weitere Bearbeitungen, wie zum Beispiel Drehen oder Einzoomen, gehen dann aber ziemlich flott von der Hand.
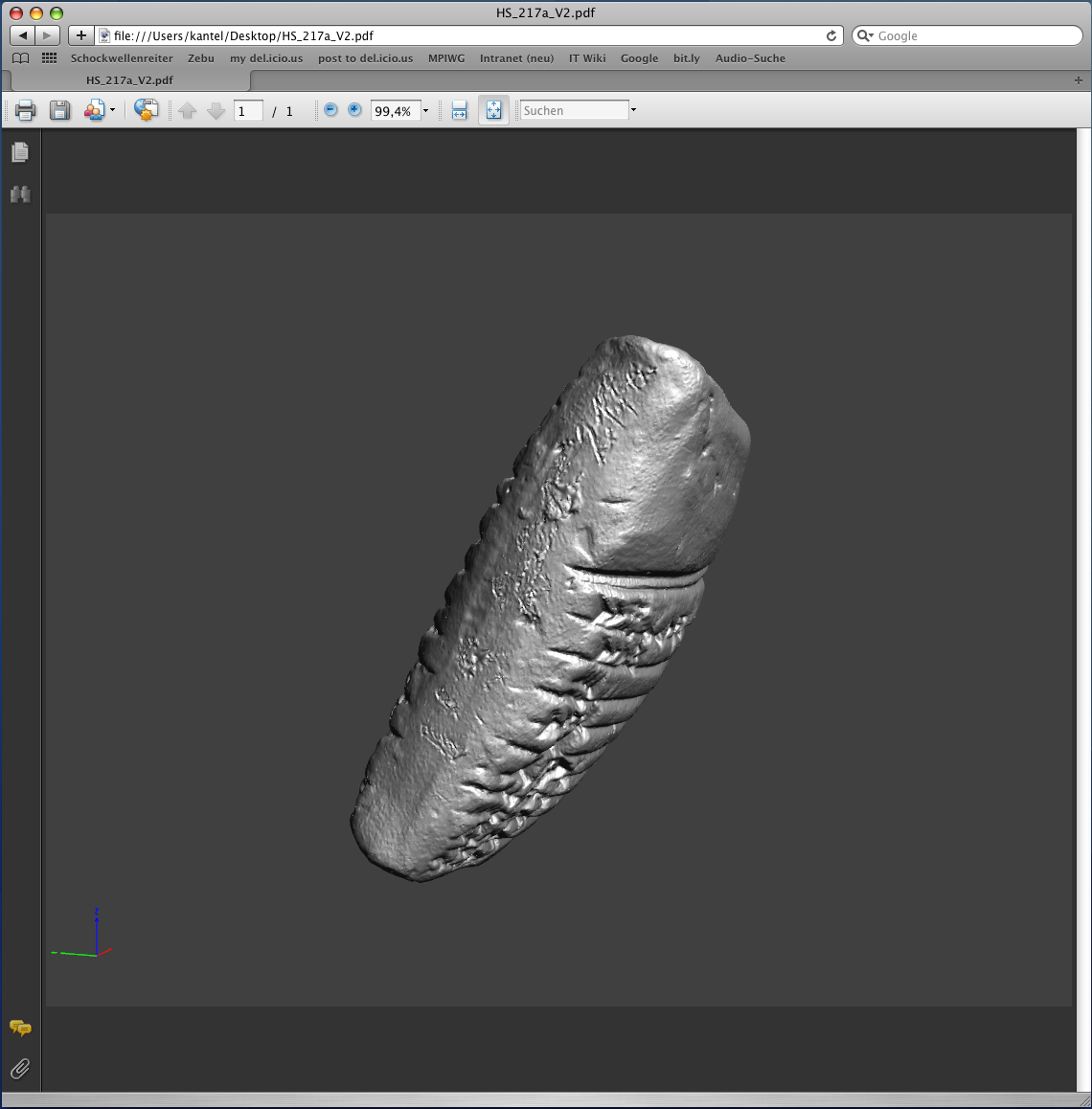
PDF 3D kann sowohl im aktuellen Adobe Reader wie auch in dem entsprechenden Browser-Plugin eingeladen und gelesen werden. Daher ist auch dies ein vielversprechender Ansatz für die Darstellung im Web, den wir weiter verfolgen werden.
Aufbereitung der Daten für den Desktop
Kommen wir nun zur Aufbereitung der Daten für den Desktop, da — wie wir oben gesehen haben — ein sinnvolles Arbeiten mit den eingescannten dreidimensionalen Keilschrifttafeln nur hier möglich ist. Dabei interessiert uns im Folgenden weniger der im Szenario 3 genannte Desktop Worker (Abbildung), der wird — als 3D-Spezialist — schon wissen, wie er die von uns zur Verfügung gestellten Dateiformate PLY und VRML in das Format seiner Wahl konvertieren kann, sondern der in der gleichen Abbildung Desktop Viewer genannte Fachwissenschaftler, der die Objekte betrachten, lesen und interpretieren will (Szenario 2).
FreeWRL
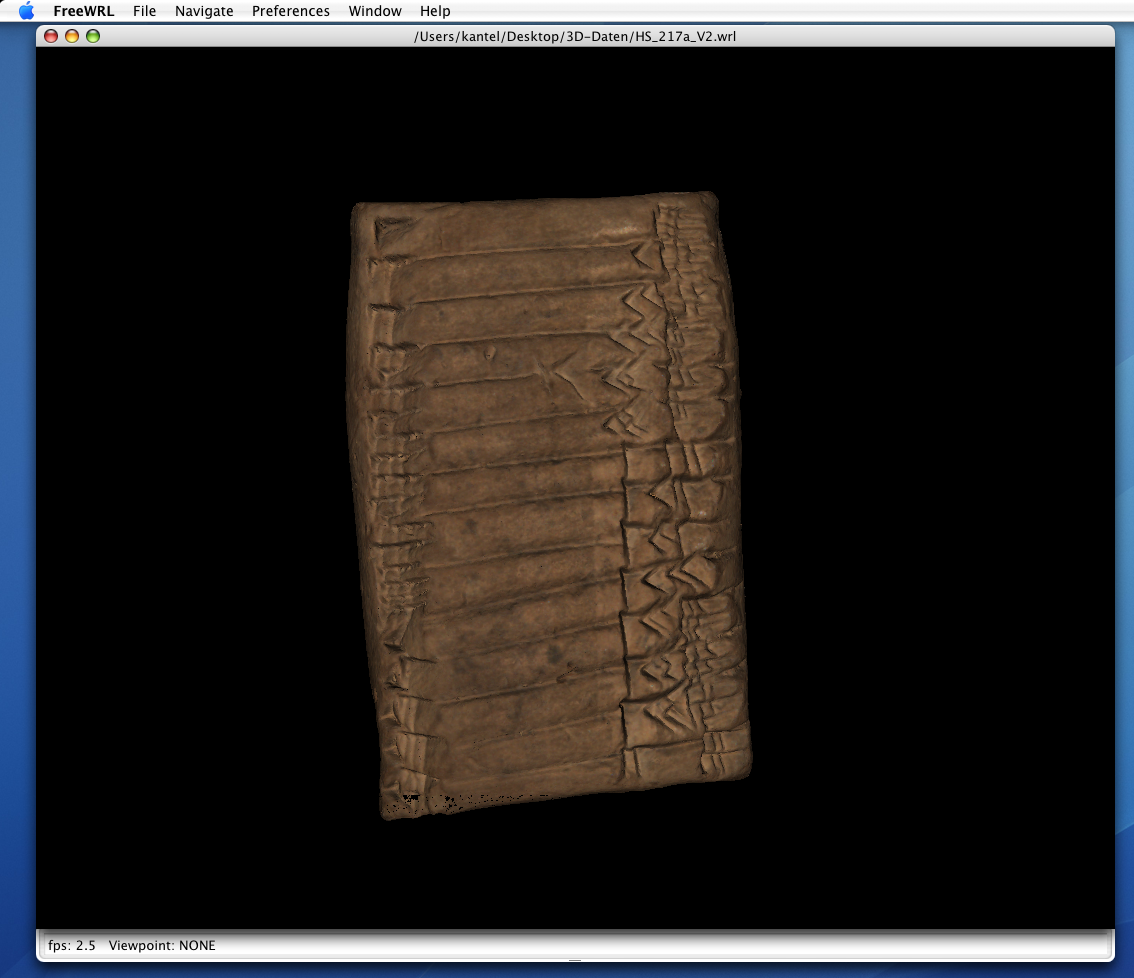
FreeWRL ist ein freier, unter einer Open-Source-Lizenz (GPL) stehender Viewer für VRML und X3D-Dateien. Es gibt Versionen für MacOS X und Linux, eine Version für Windows ist schon seit einer geraumen Anzahl von Jahren angekündigt, aber nie erschienen. Das Programm kann unter freewrl.sourceforge.net heruntergeladen werden.
FreeWLR war der erste Beweis dafür, daß die von uns mit Hilfe der Breuckmann-Software erzeugten VRML-Dateien auch tatsächlich die Farb-informationen enthielten, denn die Software zeigte diese anstandslos an.
Ansonsten ist der Funktionsumfang dieses Programmes eher beschränkt und gerade einmal für eine schnelle Vorabansicht der Tafeln geeignet, falls gerade kein anderes Programm zur Verfügung steht.
OPTOVIEW
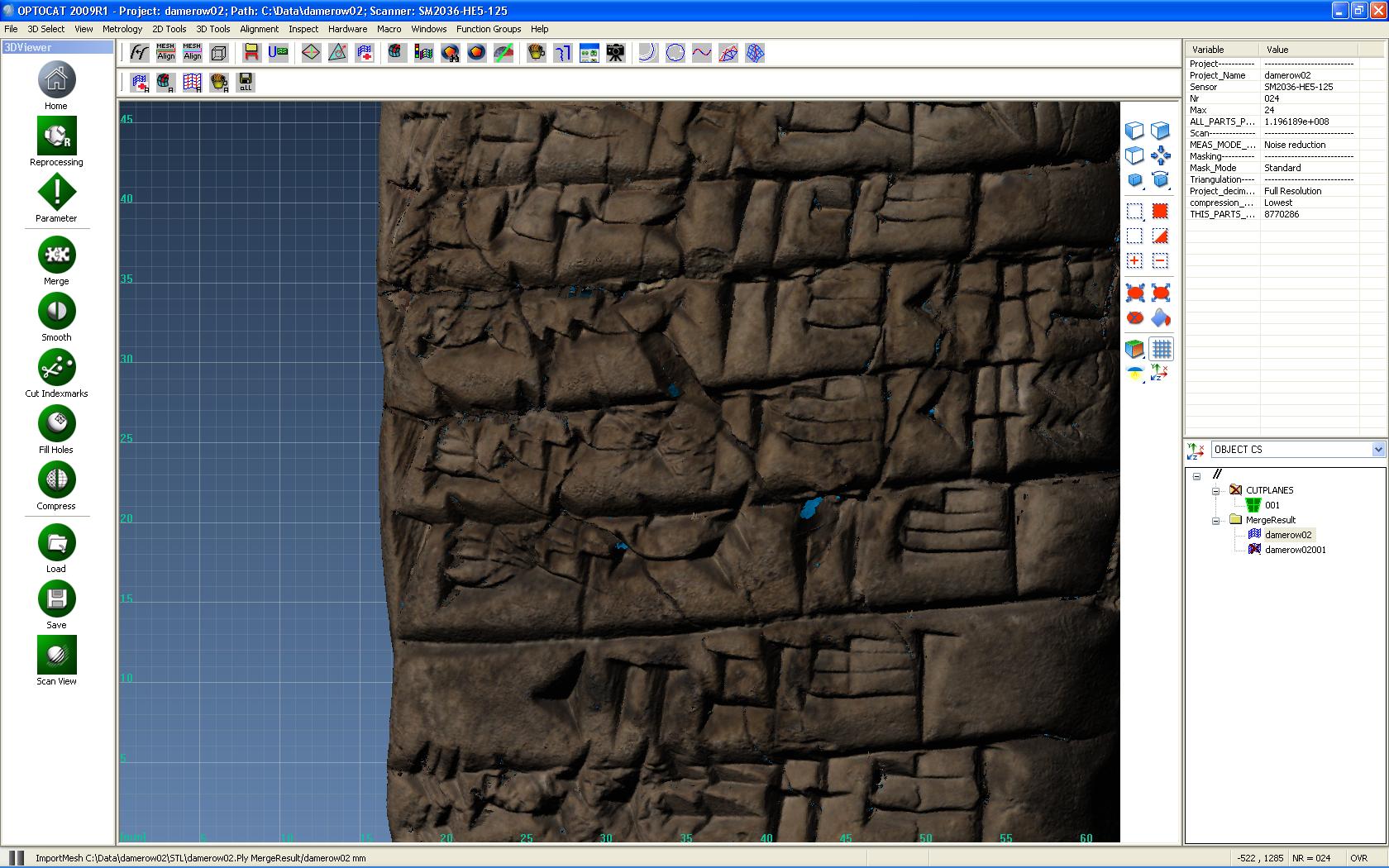
Auf Anforderung des MPIWG wurde für uns von der Firma Breuckmann eine abgespeckte Version ihrer Software entwickelt und zur Verfügung gestellt, die als Desktop-Viewer funktioniert. Dieses, OPTOVIEW genannte Programm kann von uns frei (frei wie Freibier, also nicht unter einer Open Source Lizenz) an Interessierte weitergegeben werden.
OPTOVIEW überzeugt vor allem durch die Geschwindigkeit, mit der die gerenderten Keilschrifttafeln angezeigt werden und durch die Möglichkeit, komfortabel und intuitiv bis zu vier Lichter an unterschiedlichen Orten, mit unterschiedlicher Helligkeit und in verschiedenen Farben (falls das gewünscht wird) zu setzen. Auch die übrige Bedienung weist die von uns gewohnte Breuckmann-Qualität hinsichtlich der Benutzerführung und Schnelligkeit auf. Das Programm wäre daher eigentlich das non plus ultra, das man sich für die Darstellung der eingescannten Keilschrifttafeln wünschte. Nur … es läuft ausschließlich unter Windows.
MeshLab
So hielten wir nach weiteren Alternativen Ausschau und glauben, mit MeshLab eine vielversprechende Open-Source-Lösung gefunden zu haben.
Bild meshlab1.png fehlt
Die Software ist eine Entwicklung des Instituto di Scienza e Tecnolgie dell’Informazioine „A. Faedo“ im Consiglio Nazionale delle Ricerche (ISTI-CNR). Sie kann unter meshlab.sourceforge.net kostenlos heruntergeladen werden und unterliegt ebenfalls der GPL. Es existieren Versionen für Windows, MacOS X, Linux und diverse UNIX-Derivate.
Es gibt eigentlich nur zwei Punkte, bei denen MeshLab der Breuckmann-Lösung unterlegen ist: Einmal besteht nur die Möglichkeit des Setzens einer Lichtquelle und das auch noch ziemlich unkomfortabel und zum anderen erschwert das Fehlen eines Handbuchs (ein Schwachpunkt vieler Open-Source-Projekte) das Erlernen des Umgangs mit der Software. Auf der anderen Seite bietet MeshLab viele Möglichkeiten der Filterung und Nachbearbeitung, die wir bisher noch nicht erforscht haben, die aber gerade für die Analyse der Keilschrifttafeln durchaus hilfreich sein könnten. Hier stehen wir erst am Anfang weiterer Tests.
Noch zu prüfende Möglichkeiten und weitere Ideen
Auch wenn die bisherigen Ergebnisse unserer Evaluationen gezeigt haben, daß es nicht unmöglich ist, dreidimensionale Daten auch größeren Umfangs, wie sie beim hochaufgelösten Scannen der Keilschrifttafeln entstehen, sowohl im Netz wie auch auf dem Desktop zu präsentieren und zur wissenschaftlichen Arbeit zu nutzen, haben wir sicher noch nicht alle Möglichkeiten ausgeschöpft. Auf unserer Agenda der zu prüfenden Optionen steht noch das Flash-3D-Format, mit dem man ebenfalls 3D-Thumbnails für das Web erzeugen können soll, wie die 3D-Programme 3D Studio Max, Googles SketchUp und die Produkte der AutoCad-Familie, eines kommerziellen (Quasi-) Industriestandards. Sie nutzen wiederum eigene Dateiformate, nämlich 3DS, DXF und KML. Gerade die beiden letztgenannten könnten noch interessant werden, da sie einmal Textrepräsentationen der 3D-Daten abspeichern (DXF als ASCII, KML als XML) und sie zum anderen vom Hersteller offengelegt und freigegeben, resp. im Falle von KML sogar zum ISO-Standard erhoben wurden.
Zum anderen besteht gerade für die Darstellung im Web auch noch die Möglichkeit, die 3D-Daten auf einem Server berechnen zu lassen und nur die angeforderten Ausschnitte zum Client, d.h. zum Browser, auszuliefern. (Diese Idee verdanken wir Gerd Graßhoff von der Unversität Bern, dessen digilib — die auf diese Art sehr hochaufgelöste zweidimensionale Bilder ausliefert — dafür Pate gestanden hat.) Als Basis könnte man zum Beispiel eine der freigegebenen Game Engines (wie zum Beispiel Unreal Tournament) verwenden, die von vorneherein dafür ausgelegt sind, mit großen Meshes zu hantieren. Aber während die Evaluierung der im ersten Absatz genannten Produkte sicher bald erfolgen wird, ist dies noch Zukunftsmusik.
Wie weiter?
Zur Zeit steht der Scanner sowie ein Scan- und ein Postprocessing-Rechner in Jena in der Hilprecht-Sammlung am Institut für Sprachen und Kulturen des Vorderen Orients der Friedrich-Schiller-Universität. Die Hilprecht-Sammlung ist mit über 3.300 Keilschrifttafeln nach der Sammlung des Vorderasiatischen Museums in Berlin die zweitgrößte Sammlung solcher Objekte in Deutschland. Als erstes werden dort möglichst viele der dort vorhandenen mathematischen Texte eingescannt. Wir hoffen, mit den dort gewonnenen Erfahrungen weitere Fortschritte mit der vielversprechenden Technik machen zu können.
Außerdem hatten wir — angeregt durch die Resonanz auf dem DV-Treffen — zusammen mit dem Kunsthistorischen Institut (KHI) der MPG in Florenz und dem Institut für Sprachen und Kulturen des Vorderen Orients an der FSU Jena einen Workshop zu 3D in den MPIs durchgeführt. An diesem Workshop nahmen fünf Institute der MPG, die Max Planck Digital Library (MPDL) und zwei Institutionen außerhalb der MPG teil. In unseren Augen war dieser Workshop ein großer Erfolg, der uns auch inhaltlich und technisch weiterbrachte, und das KHI wird in 2010 zusammen mit dem MPIWG einen Nachfolge-Workshop in Florenz durchführen.
Fazit
Momentan kann das dreidimensionale Scannen von Keilschrifttafeln nur als zusätzliche Option betrachtet werden. Dies ist allerdings kein prinzipielles Problem, sondern alleine der benötigten Rechenleistung geschuldet. Eine der Mitautorinnen, Christina Tsouparopoulou, hatte während der Einführungsphase des Scanners in einer Aktion in Leyden in 14 Tagen ca. 1.000 Keilschrifttafeln zweidimensional eingescannt. In diesem Zeitraum sind — unter allen günstigen Voraussetzungen und unter Nichtberücksichtigung des Post-Processings — bestenfalls ein Fünftel davon (also 200 Tafeln) dreidimensional einzuscannen.
Aber wie wir alle wissen, ist der Fortschritt in der Rechentechnik enorm. Und so vermuten wir, daß unsere Erfahrungen schon in wenigen Monaten nützlich sein können, wenn sich die Geschwindigkeit des Scan- und Bearbeitungsprozesses aufgrund schnellerer Technik beschleunigt hat. So hat das Projekt momentan noch den Status eines Piloten, aber wir sind der Überzeugung, daß in nicht allzu ferner Zukunft der dreidimensionale Scan für Objekte wie „unsere“ Keilschrifttafeln die Regel werden wird. Die Ergebnisse sind unserer Ansicht nach einfach überzeugend.
Danksagung

Wir danken Manfred Krebernik von der Hilprecht-Sammlung in Jena für die großzügige Unterstützung des Projekts und die Erlaubnis, die Objekte der Sammlung einscannen zu dürfen. Und wir danken Sebastian Schröder vom Max-Planck-Institut für Bildungsforschung in Berlin für die Hilfe sowohl bei der Evaluierung der diversen Scanner als auch bei der Untersuchung der diversen desktop- und webbasierten Viewer für 3D-Objekte. Ein weiterer Dank geht an den Leiter der Bibliothek des MPIWG, Urs Schoepflin, nicht nur für die Überlassung und Herrichtung eines der knappen Räume am Institut, in dem wir unsere ersten Scan-Versuche unternehmen durften, sondern auch für Personalmittel, die er aus seinem Etat für das Projekt bereitstellte. Er hat unsere Arbeit immer kritisch, aber wohlwollend begleitet.
Und nicht zuletzt danken wir Frau Christiane Bathow von der Firma Breuckmann, die als für uns zuständige Mitarbeiterin das Projekt immer hilfreich und engagiert unterstützt und sich einige lange Tage (und Abende) um uns gekümmert hat. Ohne sie wären wir nicht dort, wo wir heute stehen.
Für die Mitorganisation des 3D-Workshops in Jena danken wir noch einmal Manfred Krebernik aus Jena und Ute Dercks vom KHI in Florenz.
Erstveröffentlichung in: Wolfgang Assmann, Christa Hausmann-Jamin, Frank Malisius (Hrsg.): 26. DV-Treffen der Max-Planck-Institute, 22. - 24. September 2009 in Berlin, GWDG-Bericht Nr. 76, Göttingen (GWDG), 2010, S. 41 - 62